

What is Apache Hadoop Used For?
Hadoop is a free software for storing and processing immense data to maintain the platform’s serviceability so that user workloads can be managed in the least disruptive way possible. Hadoop enables clustering many computers to examine big datasets in parallel easily than using a single powerful machine for data storage and processing.
When developing a shared compute platform, numerous issues must be resolved. To avoid building software from scratch repeatedly whenever expectations can no longer be met by the current version, scalability is of utmost importance. Sharing physical resources raises concerns about isolation, multitenancy, and security.
Users that engage with a Hadoop cluster working as an ongoing service inside of an enterprise will start to rely on its dependable and highly available operation. Any compute platform must increasingly be able to expose clear but diverse application-level paradigms while abstracting the complexities of a distributed system. The compute layer for Hadoop has experienced all of this and much more during the course of its continual development. Its architecture underwent numerous evolutionary stages.
What is Hadoop Used For?
In order to replace the outdated infrastructure powering its WebMap application—the technology Apache Hadoop that creates a graph of the existing web in order to operate its search engine—Yahoo! adopted this in 2006. The web-graph at that time had over 100 billion nodes and nearly 1 trillion edges. The old infrastructure, known as “Dreadnaught,” had hit the boundaries of its scalability after starting out with only 20 nodes and successfully growing to 600 cluster nodes.
The software also struggled to handle faults in the common hardware used in the clusters in numerous instances. To scale out further to match the web’s expanding size, a fundamental change in architecture was needed. MapReduce programmes are quite similar to the distributed applications running under Dreadnought, which needed to cover a large number of machine clusters and operate at a high scale. This draws attention to the initial requirement, which would last through early iterations of Hadoop MapReduce and up to YARN Scalability.
As for Yahoo!, considerable portions of the search pipeline might be readily transferred without requiring extensive modification by using a more scalable MapReduce framework—which, in turn, sparked the early interest in Apache Hadoop. Although the initial motivation for Hadoop was to support search infrastructure, other use-cases began benefiting from it far more quickly, even before the web-graph transfer to Hadoop could be finished.
The adoption of more and bigger Hadoop clusters had been accelerated by the process of creating up research grids for research teams, data scientists, and other users. Many of Hadoop’s early requirements were driven by Yahoo! scientists who were optimising advertising analytics, spam filtering, personalisation, and content. The technical objectives changed over time in accordance with this evolution, and Hadoop went through numerous intermediate computing platform stages, including ad hoc clusters.
What is Hadoop Cluster? | What is hadoop?
A Hadoop cluster is a group of connected computers, or “nodes,” that are used to carry out these kinds of parallel operations on massive amounts of data. Contrary to traditional computer clusters, Hadoop clusters are made with the intention of storing and processing enormous amounts of organised and unstructured data in a distributed computing environment. The Name node, Resource Manager, and Node Manager all function as Masters and Slaves in the Hadoop cluster, which consists of numerous nodes (including computers and servers).
There are mainly two types of Hadoop clusters such as:
- Single Node Hadoop Cluster
- Multiple Node Hadoop Cluster
The Hadoop cluster is incredibly adaptable, which enables it to manage any kind of data regardless of its nature or structure. Hadoop can process any type of data from online web platforms thanks to its flexibility attribute.
Because the data is dispersed throughout the cluster and because of its data mapping capabilities, specifically its MapReduce architecture, which operates on the Master-Slave phenomenon, Hadoop clusters are particularly effective at working at a very fast speed.
What is Hadoop File System?
Hadoop Distributed File System is known as HDFS. Operating as a distributed file system made to function on common hardware, HDFS. Hadoop applications primarily employ HDFS (Hadoop Distributed File System) as their primary storage solution.
The open-source framework functions by sending data quickly between nodes. Companies that need to manage and store large amounts of data frequently employ it. As it offers a way to manage massive data and supports big data analytics, HDFS is a crucial part of many Hadoop systems.
In order to be deployed on affordable, commodity hardware, HDFS is fault-tolerant. HDFS facilitates streaming access to file system data in Apache Hadoop and offers high throughput data access to application data, making it suited for applications with big data sets.
Hadoop File System helps to manage large datasets, detect faults, and increase the processing speed by reducing the network traffic. There are many benefits offered by HDFS including Fault tolerance, speed, Access to different data types, portability and compatibility, Scalability, Data locality, stores immense data, and provides flexibility.
What is Mapreduce in Hadoop?
The Apache Hadoop project includes a processing module called MapReduce. Using a network of computers to store and analyse data, the Hadoop platform was created to handle large data.
Big data stored on HDFS can be processed more easily with the help of Hadoop MapReduce programming methodology.
MapReduce efficiently handles a vast volume of structured and unstructured data by utilising the resources of numerous networked machines.
This platform was the lone player in the field of distributed large data processing prior to Spark and other contemporary frameworks.
Data fragments are distributed among the nodes in a Hadoop cluster through MapReduce. The objective is to divide a dataset into manageable parts and use an algorithm to process each chunk simultaneously. Even handling petabytes of data quickly is dramatically accelerated by parallel processing across numerous machines.
Reviewing the initial Apache Hadoop MapReduce design is helpful to comprehend the new YARN process flow. Apache Hadoop MapReduce is an open-source project that has developed and improved while being a part of the Apache Software Foundation. The MapReduce programming paradigm is being implemented in this project. The main components of the Apache Hadoop MapReduce project itself can be divided into the following categories:
- The MapReduce API used by end users to programme the desired MapReduce application
- The phases of the MapReduce run-time, including the map phase, the sort/shuffle/merge aggregation, and the reduction phase, are implemented.
- The MapReduce framework is the back-end infrastructure needed, among other things, to run the user’s MapReduce application, manage cluster resources, and schedule thousands of concurrent jobs.
The ability for end users to focus solely on their application through the API and delegate handling of difficult issues like resource management, fault tolerance, and scheduling to the MapReduce run-time and framework provides substantial advantages.
As seen in Figure, the current Apache Hadoop MapReduce system is made up of a number of high-level components. The JobTracker, the cluster’s central clearinghouse for all MapReduce jobs, is the master process. TaskTracker processes on each node oversee tasks specific to that node. The JobTracker controls and communicates with the TaskTrackers.
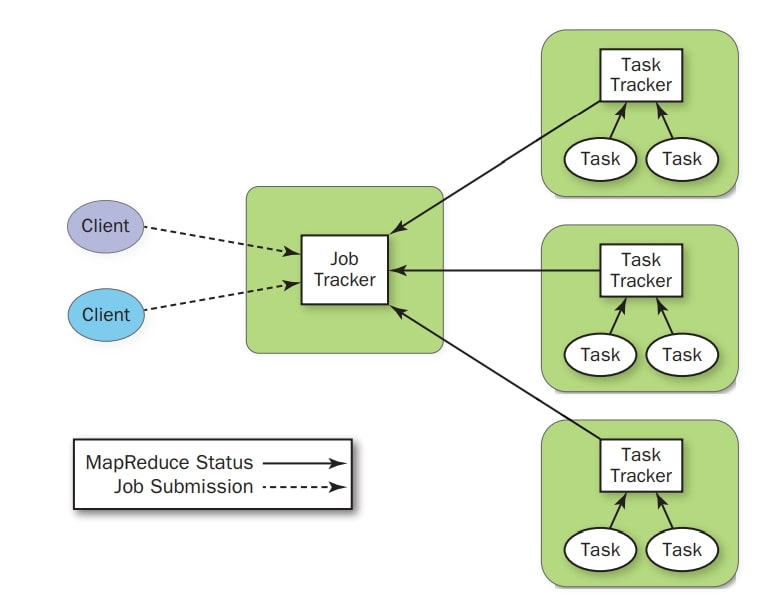
Fig: Current Hadoop MapReduce control element
What is Hadoop in Big Data?
The Big Data age is just getting started. Hadoop will keep playing a crucial part in the processing of Big Data across all industries with the help of YARN. Hadoop plays a crucial role in big data by storing and managing very large amount of data.
The preferred platform for various organizations for managing, storing, processing, and analysing big data is Apache Hadoop.
Hadoop in Big Data now have a plethora of new options available to them with the ostensibly simple separation of resource scheduling from the MapReduce data flow.
Hadoop Ecosystem | Hadoop in Cloud Computing | Cloudera Hadoop | Hadoop Architecture